RNN–递归神经网络
概述
由于传统神经网络CNN不能够记忆前一时刻的信息,所以无法处理带时间属性的数据。而事实上人类并不是每次思考问题都是从一片大脑空白开始的,而是会带着之前学习的知识来理解推断当前词的真实含义。并不是将之前所有知识抛弃。这给我一种启示,能不能有一种神经网络能够保存每时刻学习到的信息,一直推理下来。如果有的话,那么很多带有相关性属性的问题(股票预测,语音识别,机器翻译。。。)就能够有方法解决了。下面来介绍RNN模型
RNN模型
对于带序列的样本
其中x(i)代表样本在时间i处的m维特征向量
y(i)代表时间i时真实结果。
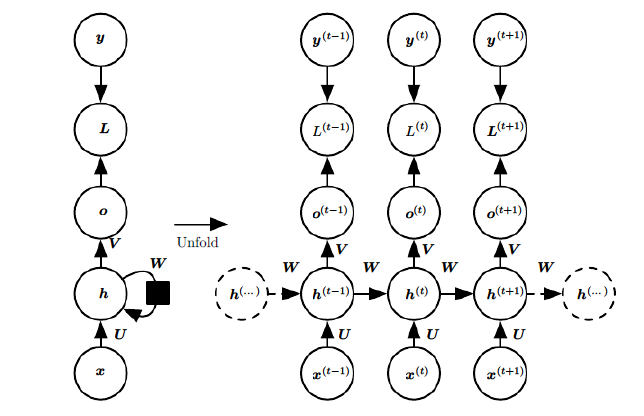
上述参数介绍:
- h(t)代表t时刻模型的隐藏状态,由h(t-1)与x(t)决定。
- o(t)代表t时刻模型的输出,只由h(t)决定。
- L(t)代表t时刻模型的损失函数,由y(t)与o(t)决定。
- W,V,U是共享矩阵,需要学习的参数。
RNN前向传播算法
对于任意一个时刻t,其隐藏状态
其中tanh(x)为激活函数,b为偏置。
输出为:
预测结果:
RNN反向传播算法
方向传播算法思路:通过梯度下降算法一轮轮迭代,得到最优的W,U,V,b,c.
由于参数W,U,V,b,c是共享的,故每次更新一样的参数。
对于RNN,假设每个时刻都有损失函数,则
其中V,c的梯度为:
U,W,b的梯度为:
又h(t)是关于U和h(t-1)的函数,h(t-1)是关于U和h(t-2)函数,由链式法则有
其中,
同理:
其中,
此时假设,若
,那么
,也就是梯度爆炸。若
,若
,也就是梯度消失。
实现RNN模型预测未来价格
- 准备数据集,对数据处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def load_data(filepath=r"data.csv", isTraining=True, days=7, input_size=1):
data = np.array(pd.read_csv(filepath,encoding="utf-8"))[:,1:input_size+1]
if isTraining:
data = data[:int(data.shape[0]*0.7), :]
else:
data = data[int(data.shape[0]*0.7):, :]
scale = preprocessing.StandardScaler()
data = scale.fit_transform(data)
x_data, y_data = [], []
for index in range(data.shape[0]-days):
x_data.append(data[index:(index+days), :])
y_data.append(data[index+days,0])
x_data = np.array(x_data).astype(float)
y_data = np.array(y_data).astype(float)
return torch.Tensor(x_data), torch.Tensor(y_data)
- 构建模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Model(torch.nn.Module):
'''定义rnn'''
def __init__(self, in_feature, hidden_feature, output_class, time_step):
super(Model, self).__init__()
self.in_feature = in_feature #输入向量维度
self.hidden_feature = hidden_feature #隐藏特征维度
self.time_step = time_step #时间步长
self.rnn = torch.nn.RNN(
input_size=in_feature,
hidden_size=hidden_feature,
batch_first=True
)
self.fct = torch.nn.Linear(
hidden_feature, output_class
)#全连接层
def forward(self, inputs):
inputs = inputs.view(-1, self.time_step, self.in_feature)
outputs, _ = self.rnn(inputs) # 输出为所以节点预测值,和隐藏值
#选取最后一个时间节点的输出
output = torch.nn.functional.tanh(
self.fct(outputs[:,-1,:])
)
return output
- 调节参数,训练模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import torch
import argparse
from utils import load_data, plot_graph
from model import Model
import pandas as pd
import numpy as np
#设置参数
parse = argparse.ArgumentParser()
parse.add_argument('--lr', type=float, default=0.1, help="learning rate")
parse.add_argument('--input_size', type=int, default=3, help="input dim")
parse.add_argument('--hidden-size', type=int, default=50, help="hidden dim")
parse.add_argument('--time_step', type=int, default=7, help="day length")
parse.add_argument('--predict_size', type=int, default=1, help="predict day lenght")
parse.add_argument('--epochs', type=int, default=2000, help="iter number")
args = parse.parse_args()
def train():
x_data, y_data = load_data(days=args.time_step, input_size=args.input_size)
model = Model(args.input_size, args.hidden_size, args.predict_size, args.time_step)
optim = torch.optim.SGD(
params=model.parameters(),
lr=args.lr,
momentum=0.9
)#动量梯度下降器
lossFuc = torch.nn.MSELoss() #损失函数为均方根
if torch.cuda.is_available: ## 判断是否有gpu
x_data = x_data.cuda()
y_data =y_data.cuda()
model = model.cuda()
for epoch in range(args.epochs):
optim.zero_grad() #梯度清零
output = model.forward(x_data)
cost = lossFuc(output, y_data)
cost.backward() #反向传播
optim.step() #梯度更新
print(
"epoch: {}".format(epoch),
"loss: {}".format(cost.item())
)
torch.save(model, r"model.pkl") #保存模型
- 调用训练好的模型来测试
1
2
3
4
5
6
7
def test():
x_data, y_data = load_data(isTraining=False)
model = torch.load(r"model.pkl")
lossFuc = torch.nn.MSELoss()
output = model.forward(x_data)
loss = lossFuc(output, y_data)
print("Test loss:{}".format(loss.item()))
